
We start with a money-saving, privacy-centric B2B stack: Membria Enterprise Edition. Once it’s battle-tested inside enterprises, the same two-tier brain populates consumer devices: PC’s, Laptops, Flagship Phones and, finally AI Live Pod, Embodied AI device
And How We’ll Get There
1 · The Enterprise Beach-head — Membria EE
- Gateway (LLM-router) decides in < 5 ms where each prompt should run and which knowledge chunks to fetch.
- Skill Forge loop distills each cloud answer into a tiny LoRA patch on the laptop—personalising the model in seconds, not hours.
Result: up to –75% inference spend (~90% of any Gen-AI budget) with 100% data sovereignty.
How it works
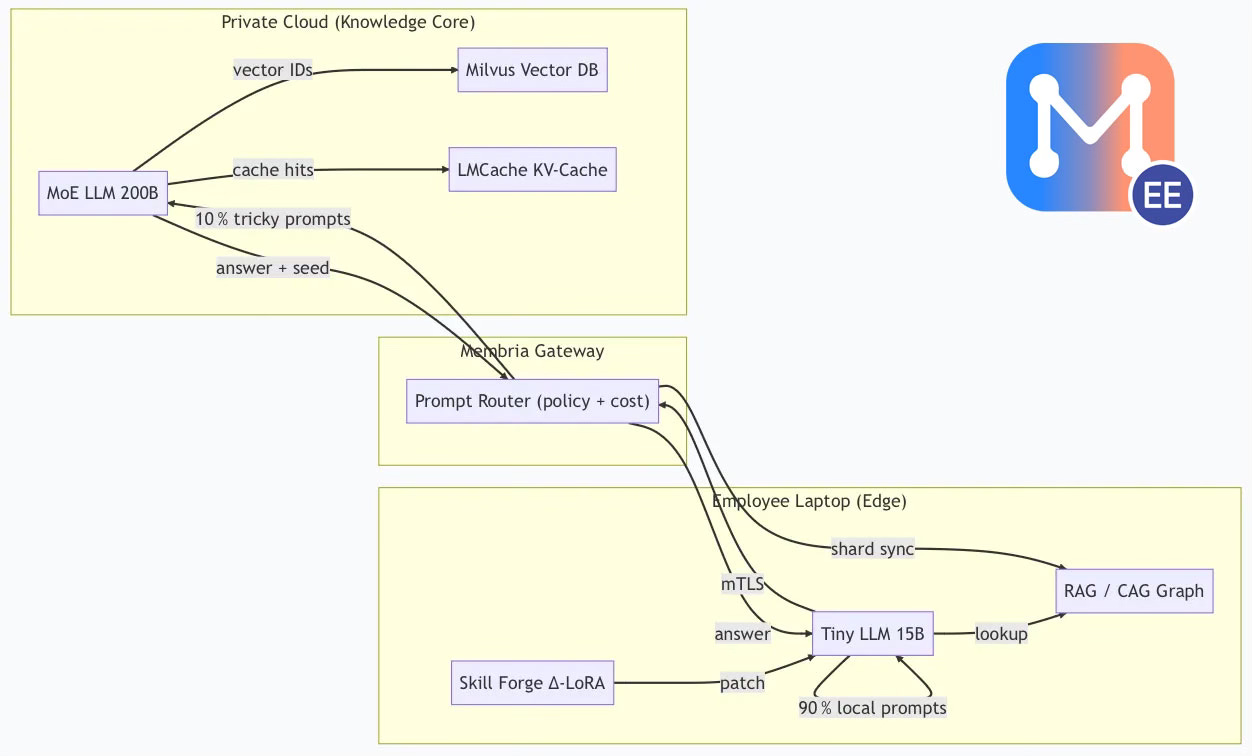
2 · From Board-room to Bed-room
Once Membria EE proves itself (predicted year-one target: –75 % GPU OPEX across energy & telco pilots), the very same brain architecture can shrink:
Because Edge handles 90% of traffic, the Knowledge Core scales elegantly: one node can serves ~100+ concurrent DoD (Distillation on Demand) requests, coming from Tiny LM to large model via Membria, not thousands of direct simultaneous user prompt queries.
3 · Why an “Embodied AI Device” Actually Rocks
Always on, always listening → perfect for context caching (when we’re stay away from work).
Relax without keyboard and mouse → NUI (Natural UI: voice, eye tracking and gestures) beats chat windows.
Household data stays inside four walls → our Edge-first philosophy in action.
In other words, the cute bedside gadget is just a different skin on the hardened enterprise AI.
4 · Roadmap Snapshot
5 · Take-aways
- Start with B2B where savings are undeniable → fund R&D.
- Two-tier design means one code-base, many devices.
- By the time competitors realize, Membria is already on the night-stand—ready to wake users with GPT-4 brains that cost almost nothing to run.
Membria: Big Brains 🤯, Small Footprint 🐾 ♻️.